A Tale of Human-parity
The most comprehensive analysis of AI benchmarks where human-parity has been reached.
Synopsis
We are in the era of human-matching AIs where the rate of task-specific AI models to reach human-parity is increasing. However, these are still different AI models and there is no single AI to do all that yet. This article presents the most comprehensive analysis of AI benchmarks where human-parity has been reached.
Analysis
Methodology
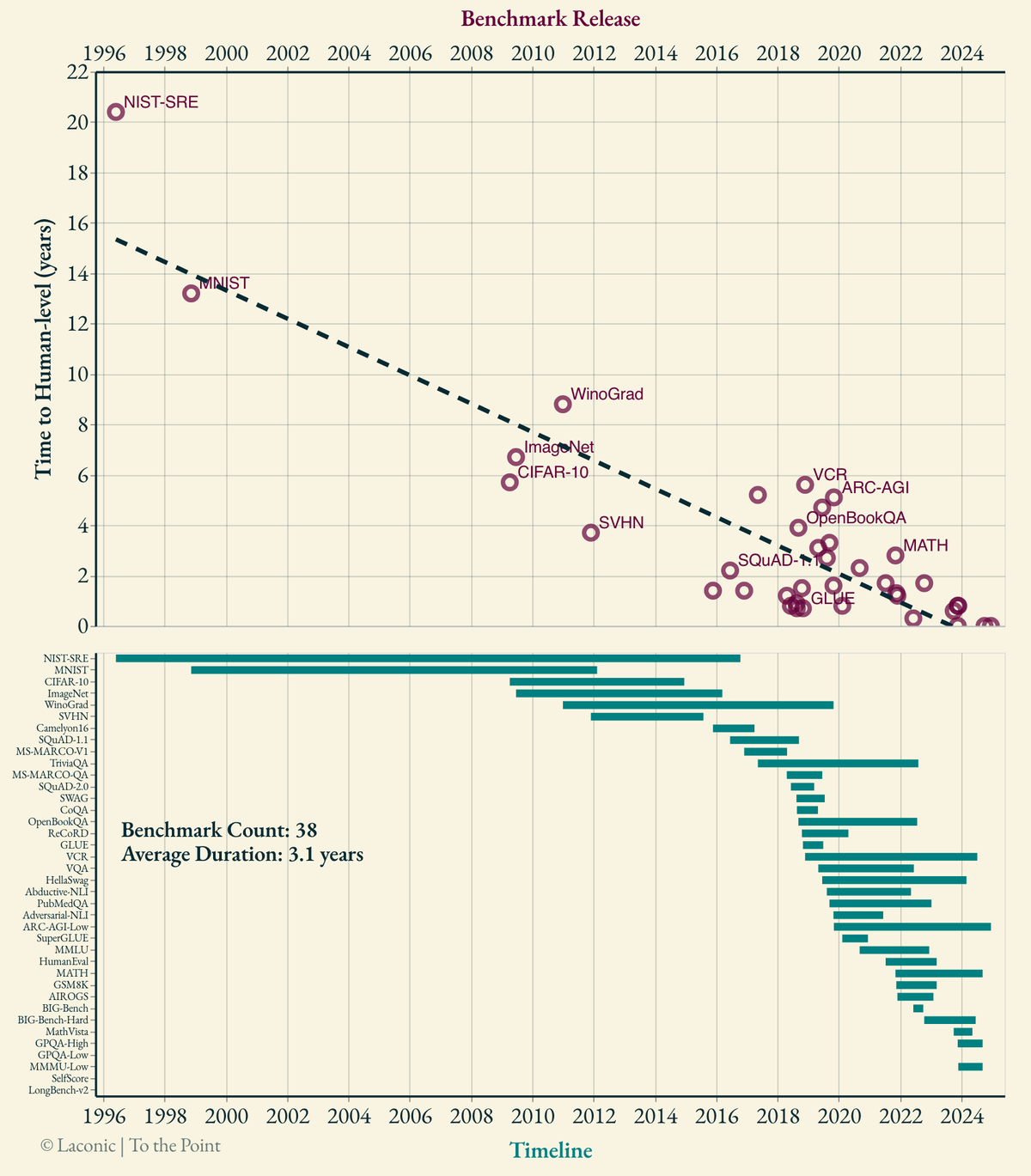
- Analysis includes various benchmarks from the last 3 decades where human baselines are reported (either by the initial benchmark creators or by other research later on). For a benchmark to be considered human-matched, at least one AI-based method (ensembles are valid as well) has to surpass the reported human baseline, i.e., coming close is not enough. Tasks are somewhat diverse, including speech recognition, reasoning, image classification, coding, medical image understanding, question answering, maths.
- Significant care was given to data curation. For example, if there is an arXiv paper with several versions (e.g. MathVista⧉), the date of the first version is considered as the benchmark Release Date. Similarly for the human-matching date, the first version to declare parity is taken rather than the latest version. These details are important and have not been paid attention to in similar analyses by others.
- There are some benchmarks that either distinguish the samples as easy/hard or the human baselines as non-expert/expert (e.g. GPQA⧉ does both). These benchmarks are separated into -Low and -High versions, indicating that the latter sets a higher bar for human-parity.
Caveats
- The most important thing to remember regarding this analysis is that by definition it can only include benchmarks where AI has already reached human performance. Therefore, there is an inherent selection bias. There are numerous benchmarks, as well as tasks that are not benchmarked where AI is still far behind humans. On the other hand, there are also a lot of tasks where human-parity is reached by AI but they are specific to a study and are not necessarily benchmarks [1, 2, 3, 4].
- Both the benchmarks and metrics are sub-optimal (wrong annotations, biases) [5, 6, 7, 8, 9, 10, 11, 12]. Data is typically quite sterile and academic, rendering the conclusions less reliable for real-life "in-the-wild" settings (it is getting better lately though). Data-leakage is rampant, especially in recent benchmarks because the field is hyper-competitive, stakes are high, and investors are dumb [13]. Confidence intervals are pretty much non-existent.
- Most benchmarks do not treat easy and hard cases (samples) separately and average out their results. Human performance for different levels of domain expertise is also not reported in most cases.
As shown in the analysis above, the duration for AI to reach human-parity is decreasing rapidly for various diverse tasks. There are already benchmarks where human-parity was reached already in day 0, i.e., when the benchmark was released. This trend is not very surprising because capabilities of all sorts of AI algorithms improve exponentially (see 4 Decades of AI Compute⧉) whereas innate capabilities of human brain stay the same (evolutionary timescales are far longer). But there is one question that will immediately render this analysis intriguing and somewhat remarkable: Is this the same AI that reaches human levels in all these benchmarks?
The answer right now (Jan, 2025) is "No, but getting there".
When Does This Become a Big Deal?
Having to create a new AI model for every different problem is not truly impressive because f.ck that; that's a lot of work◥ as we have a lot of problems. What we want is a single AI model that can perform reasonably well in various diverse tasks such as "discovering new drug molecules to battle cancer" or "generating brain-rot TikTok videos to disrupt the fabric of society by spreading misinformation, promoting shallow content, and eroding critical thinking skills". Accidental or unplanned manifestation of these capabilities (emergence⧉) would be even better. Current LLMs and multi-modal◥ frontier models are proto- examples of such AI. They showed us that it is more beneficial to focus on developing AI models with diverse capabilities than bunch of smarter specialized models. It just scales better as we have a lot of different problems.
In reality, AI research is less interested in such an AI model itself than the compact recipe to create one. In this way, researchers can focus on the higher level attributes of the AI models and try to scale general-purpose methods such as learning and search for the recipe (algorithm) part.
Napkin Math on Human Brain
Human brain has around 100 trillion synapses. Each synapse is doing something computationally similar to an FMAC⧉ per firing and fires 1-100 times/second. So its raw processing power is similar to an Nvidia H100 GPU (1014 - 1016 FLOP/second) [14]. In order to store the information in such a large neural network, hundreds of TBs is needed (even at 8-bit precision). Yet, human genome has 3.2 billion base pairs and the "human part"◥ can be compressed down to 4 MB. In summary, it is obviously not possible for the genome to contain the "weights" of the brain and it instead codes higher-level features◥. Now, that's compact!
Why is human-parity important?
AI algorithms reaching human-level performance in certain tasks is quite important because it keeps the AI investments flowing. The whole premise is easily marketable both to the investors and to the masses, to the point that any journalist, content creator, or influencer (or AI itself nowadays) can write a piece about it without having to learn anything new: AI reaches human levels in something. It does not matter who exactly is the human here, how was the comparison performed or other "superfluous" details like that.
When executives hear that AI has outperformed PhD-level mathematicians in math olympiads or similar human-matching AI news◥, they often jump to conclusions like, "If AI can do that, surely it can automate accounting—after all, accounting doesn’t require a PhD." This kind of "common-sense" reasoning, however, often falls short when applied to AI (latest example being the money thrown at Generative AI vs its RoI). The phenomenon is best explained by Moravec's paradox⧉, highlighting a counterintuitive truth: tasks that seem complex◥ are often easier for AI, while seemingly simple tasks◥ remain incredibly challenging. It is quite difficult to explain why AI can write 2000-word essays quite coherently in a few seconds yet we still don't have a robot that can pick up the clothes from the dryer and fold them into the drawer.
While entertaining◥, AI reaching human-parity is actually less important than it sounds for practical applications, mainly because
- AI is extremely useful even without human-level performance, since it scales◥. Its utility is not a step-function that suddenly multiplies right after an arbitrary accuracy threshold. Furthermore, there are numerous tasks◥ that can only be performed by machine learning algorithms and there is no such thing as human baseline for these tasks.
- Benchmark creators tend to overestimate the significance of their benchmarks. For example, creator of ARC-AGI◥ states that once his cute little puzzles are solved, it would mean "programs could automatically refine themselves" which is quite a wild, overgeneralized claim.
The Point
Task-specific AI models are reaching human-parity frantically in various benchmarks. This is less significant than it sounds. AI models increasing the diversity of their capabilities is a bigger deal, even if they don't reach human performance.
References
[1] Hendrix et al., "Development and Validation of a Convolutional Neural Network for Automated Detection of Scaphoid Fractures on Conventional Radiographs", 2021
[2] Venkadesh, "Deep Learning for Malignancy Risk Estimation of Pulmonary Nodules Detected at Low-Dose Screening CT", 2021
[3] Hendrix et al., "Artificial Intelligence for Automated Detection and Measurements of Carpal Instability Signs on Conventional Radiographs", 2024
[4] Lindner et al., "Fully Automatic System for Accurate Localisation and Analysis of Cephalometric Landmarks in Lateral Cephalograms", 2016
[5] Singh et al., "Benchmarking Object Detectors with COCO: A New Path Forward", 2024
[6] Deng et al., "COCONut: Modernizing COCO Segmentation", 2024
[7] Borchmann, "In Case You Missed It: ARC 'Challenge' Is Not That Challenging", 2024
[8] Schmidt, "Do CIFAR-10 Classifiers Generalize to CIFAR-10?", 2018
[9] Cao et al., "On the Worst Prompt Performance of Large Language Models", 2024
[10] Lu et al., "How Are Prompts Different in Terms of Sensitivity?", 2024
[11] Errica et al., "What Did I Do Wrong? Quantifying LLMs' Sensitivity and Consistency to Prompt Engineering", 2024
[12] Salinas et al., "The Butterfly Effect of Altering Prompts: How Small Changes and Jailbreaks Affect Large Language Model Performance", 2024
[13] Oprea, "Decisions Under Risk Are Decisions Under Complexity", 2024
[14] Carlsmith, "How Much Computational Power Does It Take to Match the Human Brain?", 2020
Cite This Article
Gencoglu, Oguzhan. "A Tale of Human-parity." Laconic, 27 Jan. 2025, www.laconic.fi/a-tale-of-human-parity/.
Author: Oguzhan Gencoglu
Published: 27 January 2025 | Updated: 1 February 2025